
В инструкции описан процесс установки Apache Kafka на виртуальный сервер под управлением операционной системы Ubuntu 18.04.
Что это такое?
Apache Kafka - популярный распределенный брокер сообщений, предназначенный для эффективного управления большими объемами данных в реальном времени. Кластер Kafka не только обладает высокой масштабируемостью и отказоустойчивостью, но также имеет гораздо более высокую пропускную способность по сравнению с аналогичными системами, например ActiveMQ и RabbitMQ.
Kafka обычно используется в качестве системы обмена сообщениями (публикации/подписки), многие организации также используют его для агрегации журналов, поскольку он предлагает постоянное хранилище для опубликованных сообщений.
Kafka имеет возможность обрабатывать сотни мегабайт данных чтения и записи в секунду от большого числа разных клиентов, что позволяет делать публикации сообщений в режиме реального времени без учета количества консьюмеров или способов их обработки.
Подписанным клиентам автоматически приходят уведомления об обновлениях и создании новых сообщений. Эта система более эффективна и масштабируема, чем системы, в которых пользователь должны самостоятельно и периодически проводить проверку наличия новых сообщений.
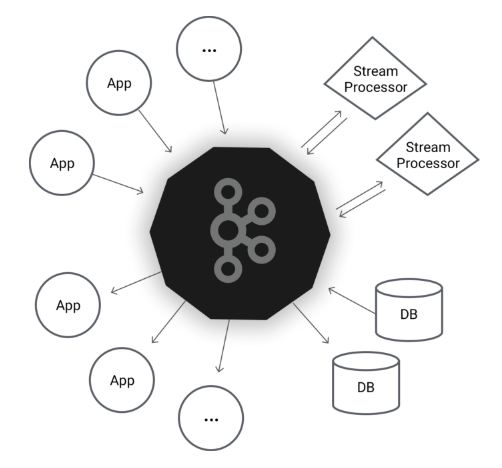
В целом, идея сервиса Apache Kafka незамысловатая. В огромной распределенной среде как правило очень много сервисов и приложений, которые генерируют разные события: логи, данные мониторинга, попытки доступа к файлам и приложениям, и прочее. С другой стороны, есть сервисы, которым эти данные очень нужны. И тут появляется Kafka: он находится между продюсерами и консьюмерами данных: собирает данные у первых, хранит у себя в распределенном хранилище по темам и раздаёт вторым по подписке. Другими словами, Kafka — это гибрид распределенной базы данных и очереди сообщений.
Kafka поддерживает работу многих популярных сервисов:
- Twitter - социальная сеть и платформа использует Kafka.Она обеспечивает отправку и получение всех пользовательских твитов, здесь пользователи читают и отправляют твиты, но незарегистрированные пользователи могут читать только твиты;
- LinkedIn использует Kafka для потока данных об активности и рабочих показателей сервиса, а также в дополнение к автономной сисеме аналитики Hadoop;
- Netflix также использует Kafka, в о сновном, для мониторинга и обработки событий в реальном времени.
В данной инструкции показан принцип работы сервиса, производится базовая установка и запуск сервера Kafka, а также проверка его работоспособности. Для внедрения продукта в бизнес используйте документацию разработчиков.
Первоначальные требования
Для настройки Apache Kafka требуется не менее 4 ГБ RAM на сервере во избежание сбоя службы Kafka и ошибки виртуальной машины Java (JVM).
Установка OpenJDK 8
Apache Kafka написана на Java, поэтому для ее работы требуется JVM, однако сценарий запуска имеет ошибку обнаружения версии, которая не позволяет запускаться системе с версиями JVM выше 8. Для установки виртуальной машины Java используйте следующую команду:
Проверить установку и версию можно с помощью следующей команды:
java -version
Создание пользователя
Kafka обрабатывает запросы по сети, поэтому необходимо создать отдельного пользователя - это минимизирует ущерб вашей машине Ubuntu, если сервер Kafka будет скомпрометирован.
Создайте пользователя:
Примечание: ключ -m означает создать домашнюю директорию для пользователя.
Установите и подтвердите пароль:
Добавьте созданного пользователя к группе sudo:
Для дальнейших настроек войдите под пользователем kafka:
su -l kafka
Загрузка файлов
В домашнем каталоге пользователя создайте каталог для загрузок:
mkdir ~/Downloads
Скачайте исходные файлы:
Создайте каталог для установки kafka и перейдите в него:
Извлеките архив, который вы загрузили с помощью команды tar:
Флаг --strip 1, гарантирует извлечение содержимого архива в ~/kafka/, а не в другой каталог (например, ~/kafka/kafka_2.12-1.1.0/) или внутри него.
Настройка сервера Kafka
Настройки по умолчанию не позволяют полноценно использовать все возможности Apache Kafka, например удалять тему, категорию, группу, на которые могут быть опубликованы сообщения. Чтобы изменить это, отредактируйте файл конфигурации:
Добавьте параметр, который позволяет удалять темы Kafka. Добавьте в конец файла следующее:
Сохраните внесенные изменения.
Создание файлов Systemd Unit и запуск сервера Kafka
Файлы Systemd Unit помогут выполнять общие действия, такие как запуск, остановка и перезапуск Kafka в соответствии с другими службами Linux.
Zookeeper - это сервис, который Kafka использует для управления состоянием и конфигурацией. Он широко используется во многих распределенных системах как неотъемлемый компонент. Более подробную информацию можно найти на сайте Zookeeper.
Создайте файл для zookeeper:
Вставьте следующие строки в файл:
В секции [Unit] указано, что для работы Zookeeper требуется, чтобы сеть и файловая система были готовы. Секция [Service] указывает, что systemd должен использовать специальные файлы оболочки для запуска и остановки службы. Последняя строка секции означает, что Zookeeper следует перезапускать автоматически, если он выходит из строя ненормально.
Далее создайте файл службы systemd для kafka:
Внесите следующие строки:
Секция [Unit] обеспечивает автоматический запуск zookeeper при запуске службы kafka. Секция [Service] указывает, что systemd должен использовать специальные файлы оболочки для запуска и остановки службы. Последняя строка секции означает, что Kafka следует перезапускать автоматически, если он выходит из строя ненормально.
Теперь, когда секции определены, запустите Kafka:
Чтобы убедиться, что сервер успешно запущен, проверьте журналы для секции kafka:
Вы должны увидеть результат, похожий на следующий:
Теперь сервер Kafka запущен и прослушивает порт 9092.
Для того, чтобы kafka включался при загрузке сервера, выполните:
Проверка установки
Давайте опубликуем и уничтожим сообщение «Hello World», чтобы убедиться, что сервер Kafka ведет себя корректно. Публикация сообщений в Кафке требует:
- producer - производитель, позволяет публиковать записи и данные по темам;
- consumer - слушатель, который читает сообщения и данные из тем.
Для начала, создайте тему под названием TutorialTopic:
Вы можете создать производителя (producer) из командной строки, используя скрипт kafka-console-producer.sh. В качестве аргументов скрипту передаются имя хоста сервера, порт и имя темы. Чтобы написать сообщение «Hello, World» в созданной теме TutorialTopic, введите:
Затем нужно создать слушателя (consumer), используя скрипт kafka-console-consumer.sh. В качестве аргументов скрипту передаются имя хоста и порт сервера ZooKeeper, а также название темы. Следующая команда принимает сообщения из темы TutorialTopic. Обратите внимание на использование флага --from-begin, который позволяет читать сообщения, которые были опубликованы до того, как был запущен слушатель:
В результате вы увидите сообщение в терминале:
Hello, World
Сценарий будет продолжать работать, ожидая большего количества сообщений в этой теме. Когда вы закончите тестирование, нажмите сочетание клавиш CTRL+C, чтобы остановить скрипт слушателя.
