
Любая техника может дать сбой, виртуальные сервера и ПО — не исключение. Проводить периодический мониторинг серверов ручным способом затратно. Именно поэтому используют автоматизированные системы мониторинга доступности и работы серверов. В статье мы разберем, что такое система мониторинга, как они работают и, что из себя представляет система мониторинга работы серверов.
Цель наблюдения
Мало просто создать компьютерную инфраструктуру. За ней нужно ещё и присматривать, ведь в ней могут возникнуть какие-то неисправности.
Причём, в данном случае не очень важно, идёт ли речь об аппаратных серверах или о виртуальных — сегодня в прикладном смысле их можно не различать.
В ходе мониторинга о наблюдаемом объекте собирают сведения, по которым можно своевременно узнать о возникновении проблемы и, соответственно, незамедлительно начать принимать меры по её устранению.
В принципе, имеются универсальные извещатели о проблемах — пользователи информационной системы. Но сообщения от них всегда приходят позже, чем о них должен был бы узнать системный администратор.
Представьте, бухгалтерская система перестала работать поздно вечером. Но её пользователи начнут сообщать о неисправности только утром, когда не они смогут исполнять свои служебные обязанности. Кроме того, не все технические проблемы сразу проявляются в пользовательском интерфейсе или проявляются в нём однозначно.
В самом простом варианте мониторинга проверяют лишь факт работоспособности наблюдаемого объекта. Однако мониторинг может выявлять не только уже возникшие проблемы, но и те, вероятность появления которых возрастает. Например, наблюдение за объёмом свободной дисковой или оперативной памяти может предупредить о приближающемся их дефицита.
Здесь следует сделать одно уточнение. Сбор данных бывает «контактным» или «дистанционным». В первом случае наблюдение ведётся программами, работающими на самом наблюдаемом сервере (их часто называют агентами). Во втором — программами, работающими на других компьютерах и наблюдающими по сети.
Во многих случаях для выявления самого факта функционирования оборудования, достаточно просто отправить ему некий запрос по сети, дождаться ответа и сравнить его с ожидаемым.
В связи с тем, что сегодня практически все информационные системы используются через интернет или, по крайней мере, через локальную сеть, далее мы будем рассматривать только дистанционный мониторинг.
За чем наблюдать?
Как уже было сказано, во время мониторинга можно фиксировать самые разные характеристики наблюдаемого объекта.
Обычно в связи с компьютерной инфраструктурой требуется проверять функционирование серверов и служб, работающих на них. В Windows по-английски эти службы называются services, а в Linux — demons или daemons.

Работу служб обеспечивает операционная система сервера. Если перестала нормально действовать операционная система, проверять работоспособность его служб бессмысленно. Но при нормально работающей операционной системе сбой в работе одной из его служб вполне возможен, и его нужно вовремя выявить.
Серверы
Для активной проверки работоспособности сервера нужно отправить ему запрос и получить ответ.
Самый простой способ проверить работоспособность сервера через интернет: отправить ему служебный запрос ping. Ответ на запрос не только подтвердит работу хоста по указанному IP-адресу, но охарактеризует качество сетевого пути.
C:\>ping 1cloud.ru
Обмен пакетами с 1cloud.ru [5.200.50.90] с 32 байтами данных:
Ответ от 5.200.50.90: число байт=32 время=3 мс TTL=123
Ответ от 5.200.50.90: число байт=32 время=3 мс TTL=123
Ответ от 5.200.50.90: число байт=32 время=8 мс TTL=123
Ответ от 5.200.50.90: число байт=32 время=3 мс TTL=123
Статистика ping для 5.200.50.90:
Пакетов: отправлено = 4, получено = 4, потеряно = 0
(0% потерь)
Приблизительное время приема-передачи в мс:
Минимальное = 3 мс, Максимальное = 8 мс, Среднее = 4 мс
Однако ping-запросы некоторые межсетевые экраны могут блокировать. В таком случае контролируемому серверу можно отправить стандартный запрос на установление соединения по протоколу TCP. Положительный ответ подтвердит работоспособность сервера.
TCP-запрос является более универсальным средством проверки работоспособности хоста. Тем не менее, если есть возможность использовать ping-запросы, лучше пользоваться ими. Они создают меньшую нагрузку на наблюдаемый сервер.
Важно понимать, что отсутствие ответа далеко не всегда означает, что сам сервер не работает. Источник проблемы может находиться в сети между наблюдателем и наблюдаемым. В таких случаях правильнее говорить не о неработоспобности сервера, а о его недоступности.
Службы
Службы (services и demons) — это программы, работающие на сервере в фоновом режиме и выполняющие какие-то прикладные или системные функции. Пример такой службы: веб-сервер (IIS, Apache, …).
В русском языке сложилось так, что сервером могут назвать и аппаратную часть, и операционную систему, и службу. Это создаёт определённую путаницу, поэтому важно уточнять, о чём в данный момент идёт речь.
В одной операционной системе может работать много разных служб. Как правило, они привязаны к разным IP-портами, поэтому их доступность можно и нужно проверять отдельно.
При этом речь уже будет идти о сетевых протоколах следующего уровня — прикладного. Например, о таких.
| Протокол | Служба | IP-порт |
| FTP | Передача файлов | 20, 21 |
| SSH | Защищённый протокол передачи данных | 22 |
| SMTP | Пересылка электронных писем | 25 |
| DNS | Служба доменных имён | 53 |
| HTTP | Веб-сервер | 80, 8008, 8080 |
| POP3 | Получение электронных писем | 110 |
| IMAP | Получение электронных писем | 143 |
| SSL | Веб-сервер по защищённому протоколу HTTPS | 443 |
| MySQL | База данных | 3306, 3307 |
Как наблюдать?
При организации системы мониторинга возникает много подзадач: откуда наблюдать, как часто проверять, как реагировать и тому подобные задачи.
Место наблюдения
Если прикладная информационная система предназначена для публичного обслуживания неограниченного круга пользователей, и она должна быть доступна из любой точки интернета, то и проверять её доступность нужно из разных мест, в которых могут находиться пользователи.
Наличие нескольких точек наблюдения позволяет сделать предварительный вывод о причине возможной недоступности сервера. Если при его очередном опросе ответ не пришёл только в часть точек наблюдения, а в другую — пришёл, это означает, что сам сервер нормально работает, а источник проблемы находится где-то на сетевом маршруте к точкам наблюдения, в которых не был получен ответ сервера.
Именно поэтому важно иметь несколько точек наблюдения, причём, достаточно разнесённых друг от друга. Конечно, здесь имеется в виду сетевая разнесённость, которая не обязательно совпадает с географической.
Периодичность
Как часто проверять доступность наблюдаемого сервера? — Вопрос непростой. Чтобы вовремя выявить проблему, опрашивать нужно достаточно часто. Но слишком интенсивные запросы могут заметно увеличить нагрузку как на сам сервер, так и на сетевую инфраструктуру.
Оптимальную периодичность следует выбирать с учётом здравого смысла и реальной потребности в быстроте выявления возможных аварийных ситуаций.
Протоколирование
Сведения, порождаемые системой мониторинга, крайне желательно где-то сохранять, например, в log-файлах или базе данных.
Эти сведения важны как сами по себе, например, для формальных отчётов или биллинга, так и в качестве источника ценной информации для последующего анализа и улучшения работы прикладной системы.
Объём протокольных данных может быть самым разным. Он зависит и от размера наблюдаемой системы, и от её характера или характеристик, и от возможностей системы мониторинга.

Автоматизация
В системе мониторинга было бы мало смысла, если она только регистрировала какие-то данные. — Данные нужно автоматически анализировать, выявлять проблемы и как-то на них реагировать.
Самая простая и очевидная реакция на обнаруженную проблему: оповещение о ней системных администраторов. Способы оповещения могут быть разными: электронная почта, SMS-сообщение, сервисы мгновенных сообщений, …
В зависимости от организации управления системой, могут быть автоматически приняты какие-то срочные меры по временному преодолению проблемы. Например, модуль управления может самостоятельно отключить неисправные серверы или переключить прикладную систему с основных серверов на резервные.
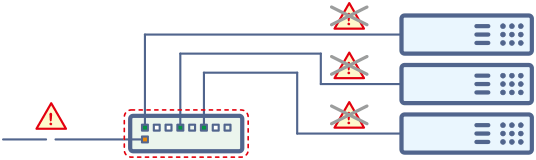
Локализация и изоляция проблемы
Когда под наблюдением находится сложная информационная система, нужно учитывать, что часть обнаруженных в ней проблем может быть следствием других, более общих.
Предположим, мы наблюдаем несколько веб-серверов, которые находятся за общим для них маршрутизатором. Если этот маршрутизатор выйдет из строя, веб-серверы окажутся недоступными из всех точек наблюдения. В такой ситуации важно правильно понять, что первопричина проблемы находится в маршрутизаторе, а не в веб-серверах.
В мощных системах мониторинга такая локализация может производиться автоматически. В менее мощных, решать эту задачу приходится самим системным администраторам.
Заключение
Ни одна, сколь-нибудь серьёзная информационная система, которая должна работать непрерывно и обслуживать значительное число пользователей, не может нормально существовать без текущего контроля её работы.
Вариантов организации наблюдения может быть много. Важно уметь выбрать наиболее подходящий.
Мы в 1cloud реализовали для своих клиентов удобный сервис, позволяющий поставить хосты (серверы, домены) на мониторинг из восьми точек: Алма-Ата, Бангалор, Лондон, Минск, Москва, Сан-Франциско, Санкт-Петербург, Франкфурт-на-Майне.
Чтобы воспользоваться мониторингом от 1cloud, вам не обязательно арендовать у нас виртуальные серверы или пользоваться другими сервисами. Услуга доступна любому зарегистрированному пользователю
P.S. О чём ещё мы пишем в нашем блоге:
- Балансировка нагрузки
- Скорость передачи данных в облаке 1cloud
- Масштабирование в облаке
- Публичность подсети
- Объектное хранилище для файлов в облаке