Поиск файлов и данных в среде Linux — это один из важнейших навыков администраторов Linux-систем. В большинстве Linux-дистрибутивов есть все необходимые программы для поиска: find и grep. Эти два мощнейших инструмента мы и рассмотрим в нашей статье, а ещё познакомимся с более современным вариантом команды grep — ripgrep.
Ищем файлы с помощью find
Командой find можно искать файлы в двух режимах: в упрощенном режиме, когда указывается только место поиска и имя файла, и в полном режиме.
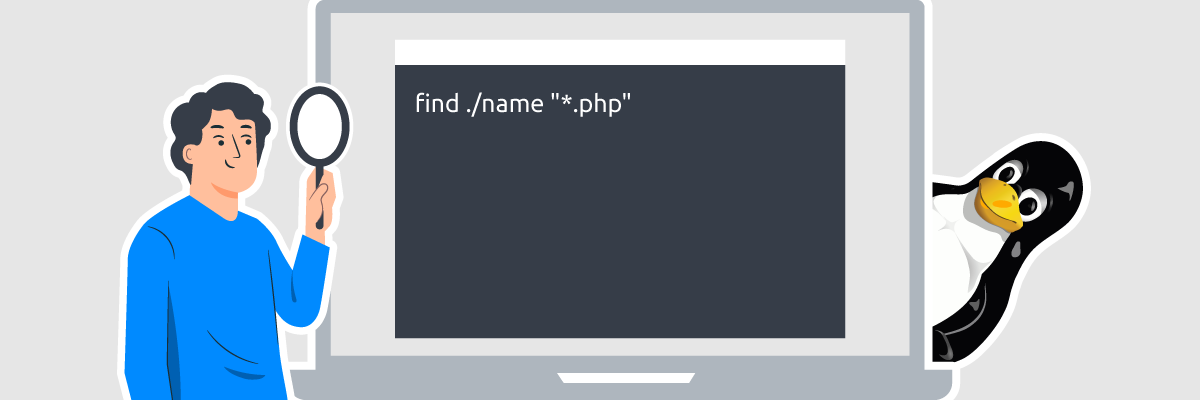
Упрощенная запись команды find выглядит так: find [где ищем] -name [что ищем]. Например, мы хотим найти все php-скрипты в директории нашего проекта cdn_test. Если мы находимся в директории, тогда команда будет выглядеть так:
find ./ -name "*.php"
Конструкция ./ — указывает на то, что поиск файлов должен осуществляться в текущей директории. Если мы находимся вне директории проекта, тогда нам необходимо указать абсолютный путь до директории проекта. В нашем случае команда будет выглядеть так:
find /var/www/cdn_test/ -name "*.php"
В обоих примерах мы использовали конструкцию *.php. Звездочка — это оператор, который указывает на то, что вместо него может быть подставлено любое значение. Прочесть *.php можно так — файл любого названия с расширением php. Оператор * очень удобен, когда нам нужно найти файл, но мы не знаем точного расширения.
Важно! Команда find с параметром -name — чувствительна к регистру, чтобы можно было искать без учета регистра используется параметр —– iname.
Полная запись команды find выглядит следующим образом: find [где ищем] [параметры поиска] [критерий поиска] [шаблон] [действие]. Давайте, разберёмся, что здесь за что отвечает:
- где ищем — это каталог для поиска;
- параметры поиска — тут указывается глубина поиска и прочие доп. параметры;
- критерий поиска — здесь задается критерий поиска: имя, дата создания, права, владелец и т.д;
- шаблон — значение, по которому будут отбираться файлы;
- действие — что делать с каждым найденным файлом.
В упрощённом варианте поиска, который мы рассмотрели ранее, мы задавали только два параметра: где искать и критерий поиска: -name — поиск по имени.
Теперь с новыми параметрами мы можем искать более точно, так как параметры поиска можно комбинировать.
Критерии поиска файлов
- Поиск по типу файла, для поиска по типу файла задается параметр -type и указывается тип файла или типы файлов через запятую для поиска. Искать можно по следующим типам:
- f – простой файл, d – каталог;
- l – символическая ссылка;
- b – блочное устройство, c – символьное устройство (dev);
- p – именованный канал;
- s – сокет.
Можно искать одновременно по нескольким типам файла, для этого искомые типы файлов указываются через запятую: -type f,l.
- Поиск по размеру файла, для поиска по точному размеру файла или диапазонам размеров файла применяется параметр -size с указанием размера файла.
Для указания точного размера файла — указывается размер файла без знаков (1M), для поиска файлов до заданного размера — указывается знак "-" (-1M), для поиска файлов больше заданного размера — указывается знак "+" (+1M).
Примеры поиска файлов по критериям размера:
find . -type f -size -1M -name "*.php" #Поиск php-скриптов меньше 1 мегабайтаТакже можно указывать диапазоны размеров файлов, для этого указывается несколько параметров -size. Сначала указывается нижняя граница размера, а затем верхняя граница. Вот пример, где мы ищем php-скрипты размером больше 3 килобайт и меньше или равно 8 килобайт.
find . -type f -size +1M -name "*.php" #Поиск php-скриптов больше 1 мегабайта
find . -type f -size 1M -name "*.php" #Поиск php-скриптов размером 1 мегабайтfind . -type f -size +3k -size -8k -name "*.php"Для указания размеров используются следующие латинские буквы: с — байты, k – килобайты, M – мегабайты, G – гигабайты. - Поиск пустых/не пустых файлов и каталогов. Для поиска пустых каталогов и файлов применяется критерий -empty. Например, мы хотим найти все пустые каталоги в директории с проектом:
find . -type d -emptyДля поиска всех пустых файлов достаточно изменить тип с d — директории, на f — файлы. Для поиска всех не пустых файлов и директорий задаётся параметр -size +1c. - Поиск файлов и каталогов по времени изменения и доступа. Для поиска файлов по времени изменения — применяются критерии -ctime и -mtime (время указывается в минутах) с указанием времени изменений, а для поиска файлов и каталогов по времени доступа — применяется критерий -atime (время указывается в днях).
Логика работы -ctime, -mtime и -atime такова:- -ctime -60 — поиск файлов и директорий изменения в которые были внесены за последний час (60 минут);
- -ctime +60 — поиск файлов и директорий изменения в которые были внесены в любое время, за исключением последнего часа;
- -mtime -1 — поиск файлов и директорий изменения в которые были внесены за последний день;
- -mtime +1 — поиск файлов и директорий изменения в которые были внесены в любое время, за исключением последнего дня.
- -atime -60 — поиск файлов, которые были использованы в последние 60 дней.
- Поиск по имени пользователя, группе и правам. Для поиска файлов и директорий по имени пользователя — используется параметр -user, для поиска по группе — используется параметр -group, а для поиска по правам — используется параметр -perm, с указанием прав в формате 777.
Посмотрим на пример поиска файлов, созданных от имени www-data (Nginx) и группы www-data:
find . -type f -user "www-data" -name "*" #Поиск по пользователю
find . -type f -group "www-data" -name "*" #Поиск по группе
А вот пример поиска файлов с правами 644:
find . -type f -perm 644 -name "*" - Поиск файлов и директорий с применением операторов. Операторы позволяют более гибко задать настройки и диапазоны поиска, так как позволяют комбинировать критерии поиска. Всего нам доступны 3 оператора: and — оператор «и», or — оператор «или», not — оператор «не».
Операторы работают, вполне, привычным способом, однако сложные комбинации имеют свою специфику записи. Круглые скобки, в которых записано условие экранируются обратным слэшем — «\».
Вот пример использования комбинации операторов «and» и «or» вместе:
find . -type f -user "www-data" \(-size +1M -size -2M -or -size +3M -size -4M \) -and -atime -100 -name "*"Здесь мы ищем файлы принадлежащие пользователю www-data, размером от 1 до 2 мегабайт или от 3 до 4 мегабайт и, обращение, к которым было за последние 100 дней.
С основными критериями, которые наиболее часто используются, мы закончили. Теперь рассмотрим другую полезную функцию команды find — выполнение действий над найденными файлами.
Развертывайте кластеры K8S за несколько минут
Управляйте кластерами Kubernetes в облаке 1cloud и запускайте контейнеризированные приложения. Managed Kubernetes Service обеспечивает высокую доступность кластера, его автоматическое масштабирование и обновление, балансировку нагрузки и интегрированный мониторинг с логированием.
Используйте MKS для быстрого создания отказоустойчивого продакшена с высоконагруженными веб-приложениями или создания множества тестовых сред.
Действие над найденными файлами
У команды find есть несколько стандартных действий обработки найденных файлов и мощный инструмент расширения возможностей постобработки результата поиска.
Начнём со встроенных действий, к ним относятся:
- -ls — отображает размер, права, владельца, группу, дату создания и абсолютный путь найденных файлов и директорий.

- -delete — удаляет найденные файлы и директории.
Теперь разберёмся с одним особенным действием, вызовом других команд с помощью -exec. Данная опция имеет множество подвидов, но мы разберем основной из них. Синтаксис exec выглядит так: -exec команда -ключ команды {} \;.
Приведем пример вызова команд через exec. Начнём с простого, вызовем команду ls -l через exec:
find . -type f -user "www-data" -size +1M -name "*" -exec ls -l {} \;
Результат работы такой команды будет таким:

Более распространенное применение exec заключается в поиске и удалении множества файлов или директорий по определенному критерию. Вот например, мы удаляем все пустые файлы в директории проекта:
find . -type f -empty -exec rm {} \;
Этот же приём можно использовать для массового копирования файлов. Например, мы хотим скопировать все картинки из папки проекта в бекап:
find . -name "*.jpg" -exec cp {} /backups/fotos \;
Что нужно запомнить про find?
Команда find позволяет искать файлы, директории, блочные устройства, сокеты по множеству критериев: начиная от даты, заканчивая временем последнего обращения к ним. Find позволяет использовать сложные наборы условий с применением операторов: and, or, not.
Встроенные действия и специальный параметр -exec позволяют создавать мощные конвейеры работы с файлами и директориями: массовое удаление, копирование, изменение по выбранным критериям поиска.
Если вам не хватает каких-то функций в команде find, например, сортировки — вы всегда можете воспользоваться оператором «|» — пайп, для передачи данных на вход другой программе. Вот пример сортировки по 6 столбцу выдачи find:
find . -type f -user "www-data" -size +1M -name "*" -exec ls -l {} \; | sort -k6
Поиск файлов и директорий — одна из самых распространённых и рутинных задач администратора Linux-систем, другая, не менее важная задача — поиск данных внутри текстовых файлов. Об этом и поговорим дальше.
Ищем внутри текстовых файлов с помощью grep

Grep — это команда для поиска внутри текстовых файлов. Она так же как и команда find есть во всех популярных Linux-дистрибутивах. Рассмотрим сначала её простое использование, а потом научимся более сложным вещам.
Фишка грепа в возможности поиска совпадений внутри множества файлов. Для этого используется параметр -r — рекурсивный поиск в каталогах. Например, мы хотим найти вхождения подстроки «Content to export» внутри всех файлов нашего проекта. Выглядеть такая команда будет так:
grep -rn --include="*.php" "Content to export" .
Тут мы применили целый набор параметров для более точного поиска вхождений:
- -r — рекурсивный поиск в каталогах;
- -n — выводить номера строк, на которых было найдено вхождение;
- --include=”*.php” — искать только в файлах с расширением php. Если этот параметр убрать — поиск будет осуществляться по всем файлам указанной директории;
- "Content to export" — вхождение, которое мы ищем;
- . — где мы ищем. В нашем случае внутри текущей директории и вниз.
Мы получили вот такой результат выполнения команды:

Grep позволяет искать и более сложные вещи, чем одно вхождение, например, мы можем найти несколько разных вхождений. Это делается с помощью специальной конструкции: 'шаблон 1\|шаблон 2'. Здесь обратный слэш экранирует оператор пайп — «|», поэтому шаблон разделяется на два шаблона: шаблон 1 и шаблон 2.
Вот как может выглядеть поиск нескольких разных вхождений:
grep -rn --include="*.php" "Content to export\|Upload content" .
Grep — утилита мощная, но старая и сегодня скорость её работы и удобства оставляют желать лучшего, однако она есть почти во всех Linux-дистрибутивах и опыт её использования может вас сильно выручить. Более современный и производительный вариант grep — это ripgrep. Работу с ним и рассмотрим далее.
Ripgrep — современный вариант grep
Ripgrep написана на Rust. Она понимает регулярные выражения, игнорирует ресурсы указанные в .gitignore, автоматически пропускает бинарные и скрытые файлы, а главное он работает намного быстрее оригинального grep.
Ещё одна сильная сторона ripgrep — это более удобный и наглядный вывод результатов поиска. Устанавливается ripgrep из репозитория apt командой apt update && apt install -y ripgrep. Вот пример вхождения подстроки «customize-control-content» во всех файлах нашего проекта, за исключением js- и css-файлов с игнорированием регистра. Такая команда будет выглядеть так:
rg -i customize-control-content -g '!*.js' -g '!*.css' .
Вывод команды будет следующим:
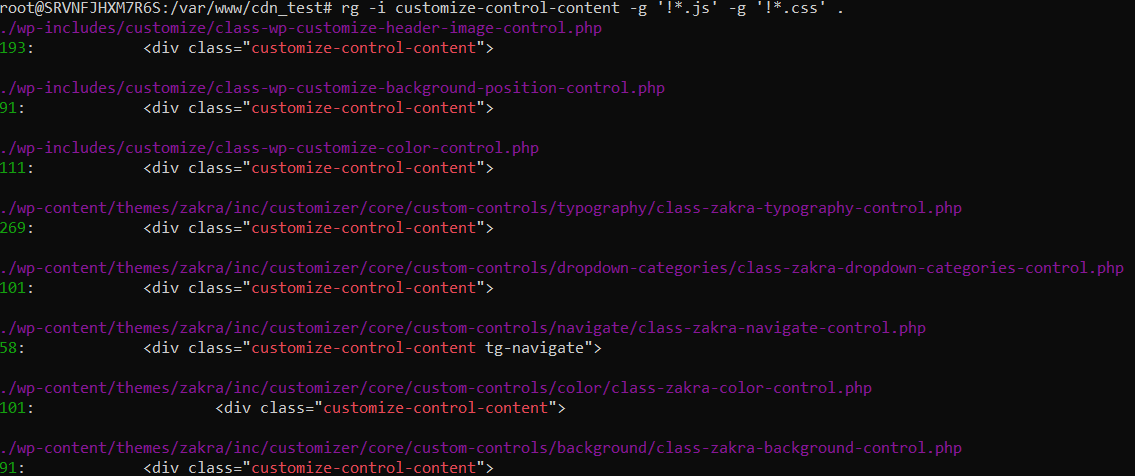
Всё наглядно и понятно. Приведём некоторые базовые ключи и приемы использования ripgrep:
- rg content main.py — поиск подстроки content в файле main.py;
- rg image . — поиск подстроки (рекурсивно) content во всех каталогах текущей директории;
- rg -i content — поиск подстроки (рекурсивно) content во всех каталогах текущей директории без учета регистра;
- rg -s content — умный поиск подстроки (рекурсивно) content во всех каталогах текущей директории;
- rg -F '(?.content)' — поиск с учетом специальных символов без экранирования;
- rg content -g '*.py' — поиск подстроки content только в файлах с расширением .py;
- rg content -g '*!*.py' — поиск подстроки content во всех файлах кроме файлов с расширением .py;
- rg -l content — показать только название файлов, где найдена подстрока content;
- rg -v content — инвертированный поиск. Показывает файлы, где не найдена подстрока content;
- rg --count content — показать количество строк с найденным вхождением подстроки content;
- rg --count-matches content — показать количество вхождений подстроки content в файле;
- rg content --stats — вывести отчет о количестве найденных построчных совпадений, вхождений, количестве файлов;
- rg content --sort modifi/path — отсортировать полученный список совпадений по времени изменения или пути.
Ключи и опции поиска можно комбинировать. Вот в этом примере, мы применили сразу 4 опции поиска: показали только названия файлов(-l), искали вхождения подстроки content только в файлах с расширением .js (-g), подсчитали количество строк с вхождением подстроки в каждом файле (--count) и отсортировали вывод по времени изменения файлов (--sort modified):
rg -lg "*.js" content --count --sort modified
Итак, мы рассмотрели работу с двумя версиями команды grep: классической версией и современной версией — ripgrep, а также разобрались в том, как эффективно искать файлы с помощью утилиты find. Давайте соберем все новые знания воедино.
Что мы узнали про find, grep и ripgrep?

Find — это утилита для поиска файлов, директорий, сокетов, блочных устройств по множеству критериев, с возможностью выполнения различных действий над файлами: сортировки, удаления, копирования. Вы также можете использовать операторы условий: and — «и», or — «или» и not — «не» внутри команды find.
Find имеет специальный параметр -exec, который позволяет передавать результаты поиска в любую другую программу. Если стандартных функций find вам не хватает, всегда можно воспользоваться оператором пайп («|») и построить конвейер любой сложности.
Grep — это утилита для поиска подстроки в файлах со множеством опций отражения результата: сортировки, скрытия лишней информации, отчетов. С помощью grep можно искать вхождения как в одном файле, так и во множестве файлов или директорий по заданным условиям.
Современная, более удобная и быстрая версия grep — ripgrep. У неё более понятный и удобный синтаксис записи и более высокая скорость работы.
Без сомнения умение искать информацию в независимости от её месторасположения и формы — это один из главных навыков любого Linux-администратора, но не единственный навык. В нашем блоге вы найдёте статьи, которые помогут вам начать работать с утилитами, командами и горячими клавишами Linux:

3 утилиты Linux для работы с VPS
Разбор 3 утилит, с помощью которых можно быстро подключиться к VPS и удобно работать на них.

10 команд Linux для начинающих
Изучаем 10 команд терминала Linux, знание которых сильно облегчит работу новичка в среде Linux.

10 горячих клавиш Linux для начинающих
Приводим 10 хоткейсов терминала Linux для новичков, которые позволят работать с терминалом эффективнее.