В предыдущей статье мы рассказали о том, как развернуть систему мониторинга, состоящую из node exporter, alertmanager, prometheus и grafana с помощью Docker на одном сервере — локально. Это было просто — пара Docker-команд, немного настроек и всё. В этой статье мы повысим градус «хардкорности» материала: посмотрим, как устанавливаются и взаимодействуют элементы системы мониторинга между собой, научимся устанавливать и настраивать распределенную систему мониторинга.
В следующей статье мы рассмотрим процесс установки, настройки и подключения Grafana к Prometheus, а чуть позже мы поднимемся на уровень выше — автоматизируем развертывание распределенной системы мониторинга с помощью Ansible. Статья большая, и чтобы было легче в ней ориентироваться — можно воспользоваться оглавлением:
Давайте сразу к делу — начнем с разбора того, что такое Exporters и зачем они нужны.
Exporters
Exporters — это программы, которые собирают метрики на хостах и предоставляют к ним доступ на определенном HTTP-порту. Самым распространенным экспортером является node exporter, он собирает метрики ОС и «железа».
Есть и другие exporters:
- Blackbox exporter — сбор метрик внешних сервисов через HTTP, HTTPS, DNS, TCP, ICMP. Порт для доступа по умолчанию — 9115;
- Consule exporter — сбор метрик из Consule, ПО от Hashicorp, которое обеспечивает регистрацию и хранение информации о работающих IT сервисах в сети организации. Порт для доступа по умолчанию — 9107;
- Graphite exporter — сбор метрик из системы мониторинга Graphite. Порт для доступа по умолчанию — 9108;
- HAProxy exporter — сбор метрик web-сервера HAProxy. Порт для доступа по умолчанию — 9101;
- Memcached exporter — сбор метрик Memcached, сервиса кэширования данных в оперативной памяти на основе хеш-таблицы. Порт для доступа по умолчанию — 9150;
- Node exporter — сбор системных метрик (процессор, память, и т.д.). Порт для доступа по умолчанию — 9100;
- Mysql exporter — сбор метрик работы сервера MySQL. Порт для доступа по умолчанию — 9104;
- Postgres exporter — сбор метрик работы сервера PostgreSQL. Порт для доступа по умолчанию — 9187;
- Pushgateway — сбор метрик сервиса Pushgateway, куда попадают метрики, когда стандартная pull-модель prometheus не применима. Порт для доступа по умолчанию — 9091;
- Statsd exporter — сбор метрик Statsd-демона, написанного на Node.js, который агрегирует и суммирует метрики, полученные из разных приложений. Порт для доступа по умолчанию — 9102.
Экспортеры устанавливаются на наблюдаемые хосты и предоставляют доступ к метрикам в формате plain-text на указанных выше портах. Конечно, вы можете установить несколько экспортеров на хост и снимать целевые метрики с них. Так же многие экспортеры могут быть настроены для предоставления только нужных вам метрик.
Как мы говорили ранее одним из самых популярных экспортеров является Node exporter. Вот о нём и поговорим детальнее, ведь способы его установки и настройки подходят для многих других экспортеров.
Node exporter
О том, как правильно установить и запустить node exporter можно почитать в статье — «Установка, настройка и запуск Node exporter». Мы же сейчас рассмотрим процесс работы с node exporter. По умолчанию node exporter работает на порте 9100 — введем в браузере [IP-адрес нашего сервера]:9100 и перейдем во вкладку metrics.
Мы увидим следующее:
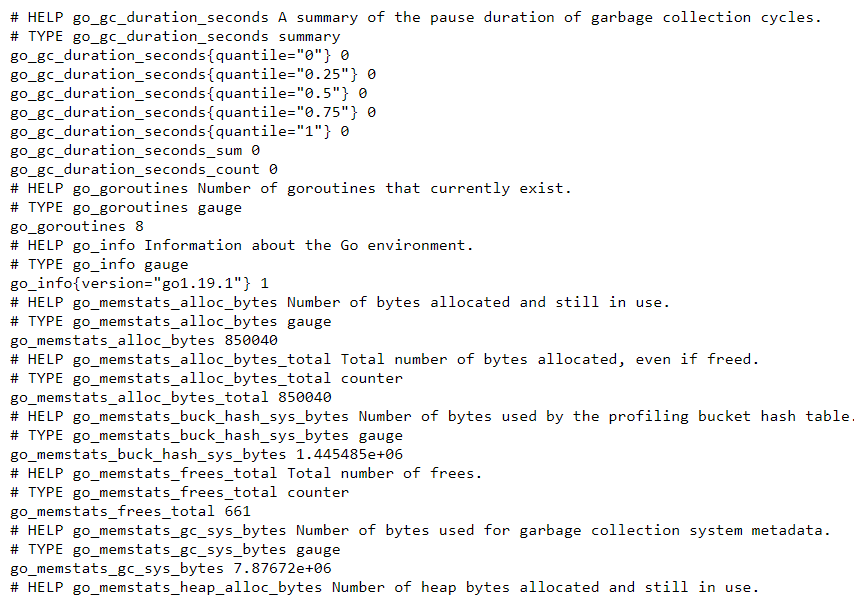
Метрики представлены в виде простой plain-text html-страницы. Это сделано для удобства её парсинга. Например, можно забирать данные с помощью самописных скриптов на bash, python и прочих ЯП. Сами метрики состоят из названия, значений и иногда дополнительных данных или значений, заключенных в фигурные скобки. Такие метрики называют составными или сложными:
Метрики собираются так называемыми «коллекторами», которые можно включать и выключать с помощью директив при запуске node exporter. Это бывает очень полезно, когда у вас много наблюдаемых серверов, с которых нужно собирать много метрик. Вот пример unit-файла node exporter, где мы выключили несколько коллекторов и включили коллектор для сбора CPU-метрик:
[Unit]
Description=NodeExporter
[Service]
TimeoutStartSec=0
User=node_exporter
ExecStart=/usr/local/bin/node_exporter \
--web.listen-address=:9100 \
--no-collector.arp \
--no-collector.bcache \
--collector.cpu
[Install]
WantedBy=multi-user.target
Ознакомиться с полным списком коллекторов и способами работы с ними можно в официальном репозитории разработчиков на GitHub. К сожалению, опции выключить все коллекторы и включить только нужные — нет.
Кратко об exporters
Exporters — это программы, которые снимают метрики с процессов и представляют их в виде человекочитаемых данных на определенном http-порту. Существует множество экспортеров для различных метрик, снимаемых с процессов в ОС и специализированного софта: web-серверов, SQL-СУБД, хеш-СУБД и т.д.
Устанавливаются экспортеры, как правило, двумя путями:
- скачиваются в виде бинарных файлов, готовых к запуску из официальных репозиториев с помощью wget, git clone;
- скачиваются в виде исходников и собираются на локальных машинах.
Собираемые и транслируемые на http-порт данные забирает Prometheus, но благодаря простому text-plain формату данные легко парсятся и могут быть переиспользованы другими программами. Итак, с тем, что такое экспортеры, какие они бывают и как работают — разобрались. Настало время познакомиться с Prometheus.
Prometheus
Prometheus — это система мониторинга и оповещения о событиях, хранящая данные в виде временных рядов. Prometheus так же как и node exporter — это программа, один бинарный файл, который запускается в качестве демона и собирает данные полученные от node exporter в заданное в конфигурационном файле место. В отличие от многих других СУБД, например, PostgreSQL, Prometheus сам опрашивает указанные в конфигурационном файле серверы и порты.
Скачать Prometheus можно из репозитория разработчиков с помощью wget или git clone. Настраивается он непросто. В нашей базе знаний есть подробная статья по установке и настройке Prometheus — переходите и пользуйтесь.
Работа в Prometheus
По умолчанию web-интерфейс Prometheus работает на порте 9100. При заходе в него, вы увидите такой интерфейс:
Это главное окно Prometheus. Здесь вводятся запросы к БД, строятся таблицы и графики. Для того чтобы просмотреть статистику по какой-либо метрике — нужно ввести запрос в строку поиска:
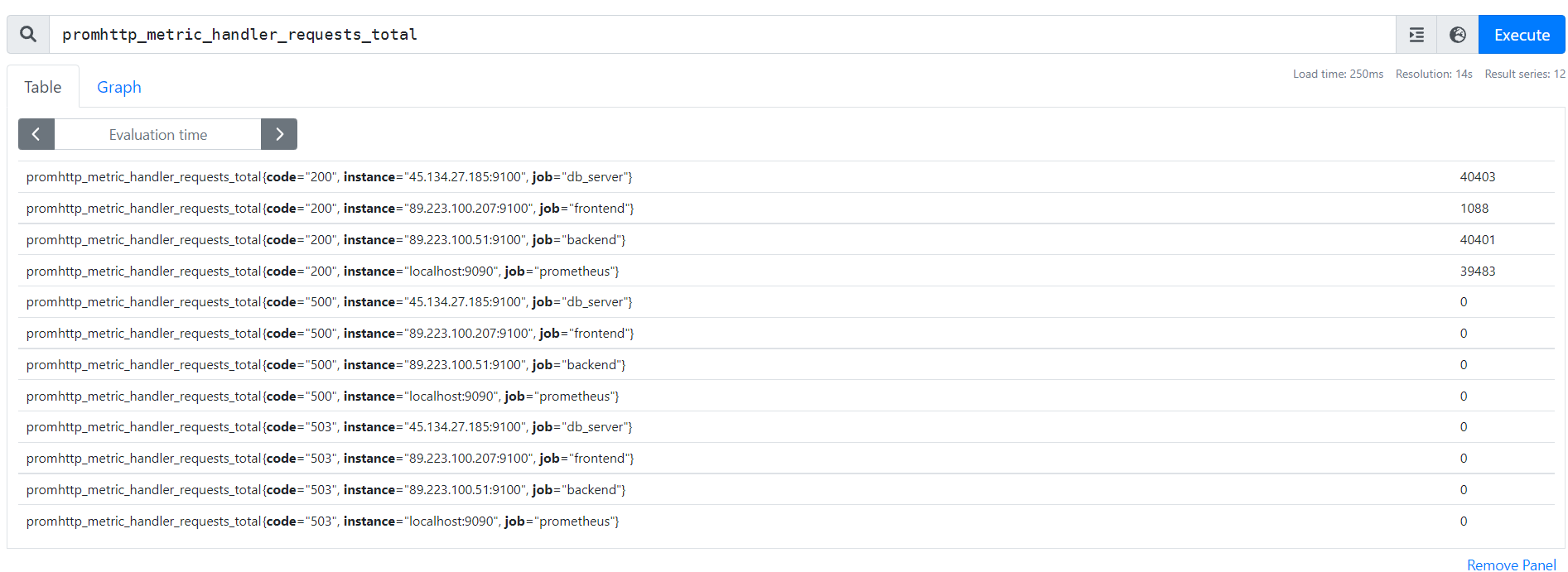
Запрос может представлять собой: просто название метрики, название метрики и метки, название метрики, метки и параметры выборки. Названия метрик можно взять из выдачи node exporter. Вот, например, мы вывели количество http-запросов с кодами ответов к нашим серверам. Названия метрик мы нашли через Ctrl+f в Chrome на странице выдачи node exporter:

Для точных выборок метрик используются метки. Они указаны в фигурных скобках. Например, мы хотим получить данные по http-запросам с кодом 200 относящиеся только к фронтенд серверу — сделать это можно вот таким запросом:
promhttp_metric_handler_requests_total{code="200",job="frontend"}
В результате такого запроса, мы получим такой результат:

Если рассмотреть вывод метрик node exporter более внимательно, то можно заметить, что каждая секция коллектора начинается с двух строчек вводной информации: первая строчка — это краткое описание собираемой статистики, а вторая строчка — описание типа метрики. Есть 4 типами метрик (2 простые метрики и 2 составные):
- Counter — это просто линейный счетчик, который может только увеличиваться. Например, количество посетителей сайта;
- Gauge — это двунаправленный счетчик, значение которого может как увеличиваться, так и уменьшаться. Например, количество потоков в ОС;
- Histogram — это комбинация различных счетчиков, используется для отслеживания размерных показателей и их продолжительности, таких как длительность запросов;
- Summary (Сводка) работает как гистограмма, но также рассчитывает квантили.
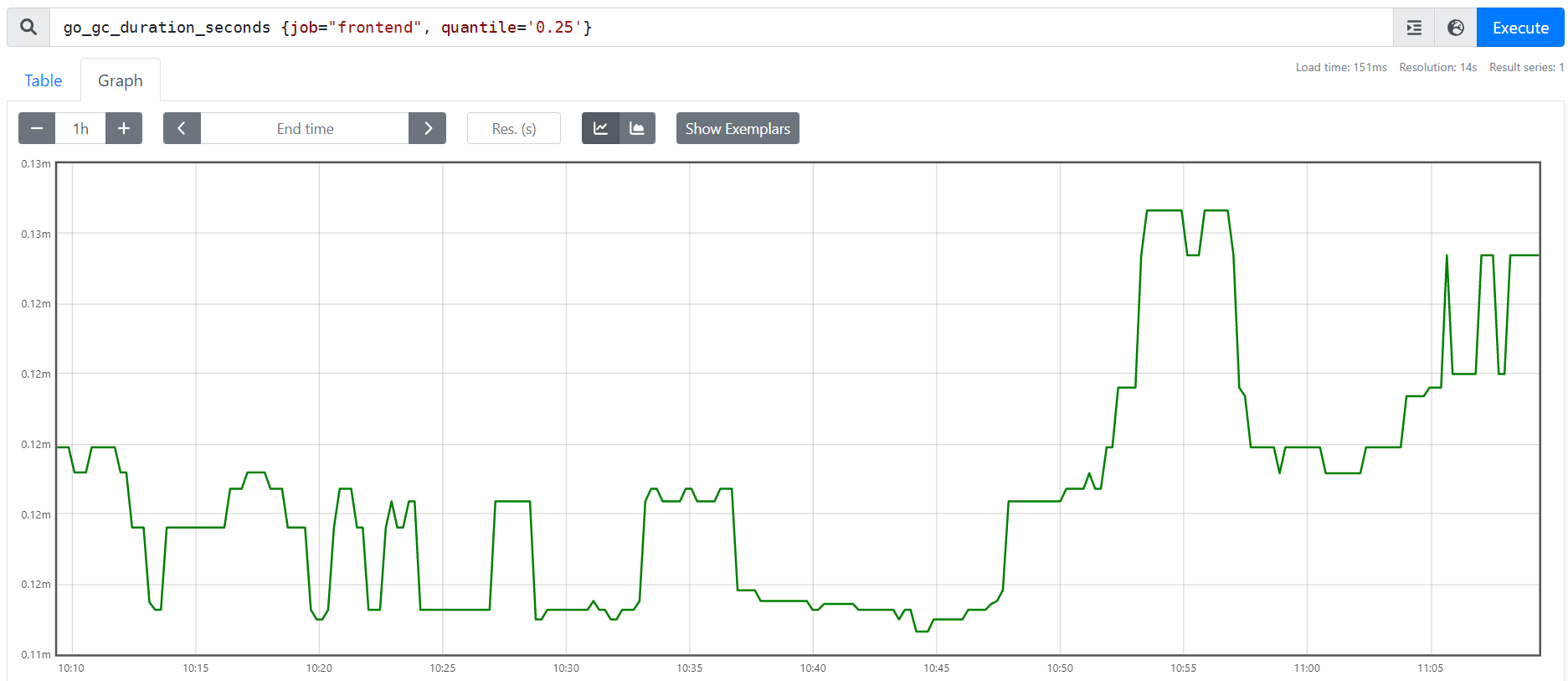
Типы метрик gauge, histogram и summary подходят для построения графиков. Вот, например мы строим график по метрике go_gc_duration_seconds, которая отражает время продолжительности вызова GC (Go client) для frontend-сервера со значением квантиля в 0.25:
Для формирования запросов в Prometheus используется язык запросов для TSDB — PromQL, он же используется и в Grafana. PromQL мощный, функциональный и относительно простой язык запросов, позволяющий использовать агрегаторы и операторы. Это значит, что вы можете делать сложные выборки по многим параметрам и производить с ними математические операции.
Вот например, запрос, который возвращает объем свободной памяти на наблюдаемом сервере в байтах, которые мы сразу перевели в мегабайты, с помощью оператора деления:
node_memory_MemFree_bytes / (1024 * 1024)
Так мы можем узнать процент свободной памяти на сервере и создать на базе этого запроса сообщение, при критическом уровне свободной памяти менее 5%:
round((node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100) #Узнать остаток свободной памяти
round((node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100) < 5 #Условие оповещения при критическом остатке свободной памяти менее 5%
Конечно, можно строить и более сложные запросы для нескольких метрик, сравнивать их между собой, находить среднее и много-много другого, но вы этим скорее всего заниматься в Prometheus не будете, так как важнее быть в курсе текущей ситуации по всей инфраструктуре и оперативно реагировать на инциденты.
Именно о сценариях инцидентов и алертах мы поговорим далее, а пока подведем краткое резюме.
Кратко о Prometheus
Prometheus — это система мониторинга и оповещений, хранящая и обрабатывающая метрики, собираемые из экспортеров в Time Series Database (TSDB). В отличие от SQl-like СУБД, Prometheus сам собирает метрики по указанным хостам.
Для работы с метриками в Prometheus используется язык запрос PromQL. Он позволяет составлять сложные запросы и использовать математические операторы. Результат запроса может быть выведен в табличной или графической форме.
Сами данные хранятся в виде набора файлов на жестком диске сервера, где установлен Prometheus. Через конфигурационный файл Prometheus можно настроить длительность хранения данных и задать объём дискового пространства для хранения данных.
Также Prometheus может оповещать, о различных событиях, которые настраиваются администратором Prometheus в специальном конфигурационном файле alerts. Для удобной и корректной работы системы оповещения применяется специальное расширение — AlertManager. О нём и поговорим далее.
AlertManager
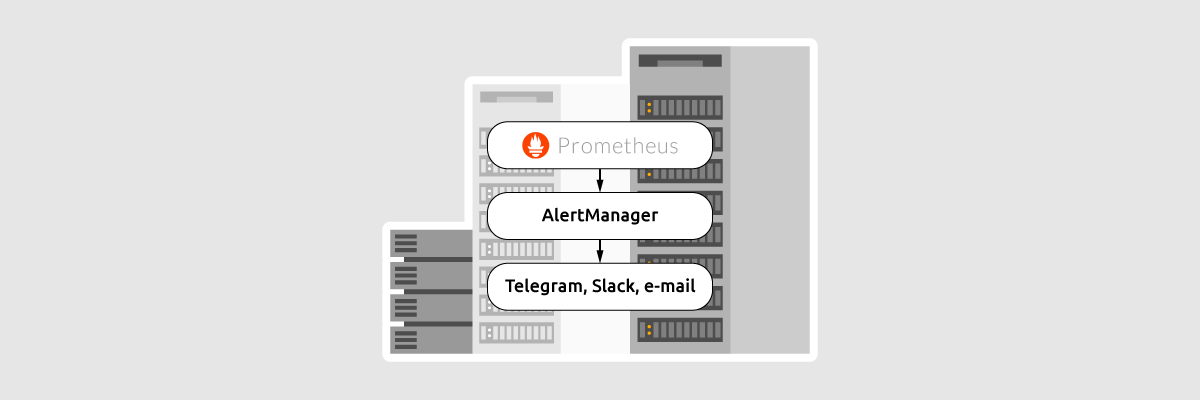
AlertManager — это менеджер оповещений об инцидентах, который работает в паре с Prometheus. Алерты на события генерирует сам Prometheus, однако если состояние сервера совпадает с правилом Prometheus будет генерировать алерт при каждом обновлении — это, конечно же, не удобно, поэтому используют AlertManager. Он умеет их группировать и высылать оповещения по заданным критериям.
Работает этот симбиоз так: в специальном alert-конфиге Prometheus создаются правила алертов, когда они срабатывают, Prometheus отправляет их в AlertManager, который уже ими управляет: подавляет, объединяет, отправляет уведомления на разные платформы. Выглядит непросто, но мы во всем разберемся. Начнем с того, что AlertManager нужно установить. Инструкцию по установке AlertManager можно найти здесь.
После установки AlertManager можно приступать к созданию правил уведомлений.
Настройка алертов
Удобнее всего создавать правила для уведомлений в отдельном файле и подключать его к основному конфигу Prometheus. Так и сделаем. Создадим простое правило, которое будет слать нам уведомления при недоступности наблюдаемых хостов:
- Создадим файл с правилами — vim /etc/prometheus/alerts.yml;
- Запишем в файл следующие:
groups: - name: Critical alerts rules: - alert: InstanceDown expr: up == 0 for: 1m labels: severity: critical annotations: description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minute.' summary: Instance {{ $labels.instance }} downestart=on-failure - Проверим файл на синтаксис и валидность правила командой promtool check rules /etc/prometheus/alerts.yml. Если тест вернул success — можно двигаться дальше, если нет — проверьте отступы и условия алерта;
- Подключим наше правило в конфиге Prometheus:
- vim /etc/prometheus/prometheus.yml;
- Находим секцию rule_files и добавляем в неё наш файл с правилами:
 Обратите внимание на отступы перед знаком «-» — там идут 2 пробела. Если их не поставить, yml может читаться не корректно.
Обратите внимание на отступы перед знаком «-» — там идут 2 пробела. Если их не поставить, yml может читаться не корректно.
- Перезапустим Prometheus командой systemctl restart prometheus;
- Проверим статус работы Prometheus командой systemctl status prometheus;
Теперь можно переходить в раздел Alerts. После подключения правила мы увидим его название и статус:

Сейчас всё нормально все наши хосты доступны. Остановим frontend сервер и увидим следующую картину:
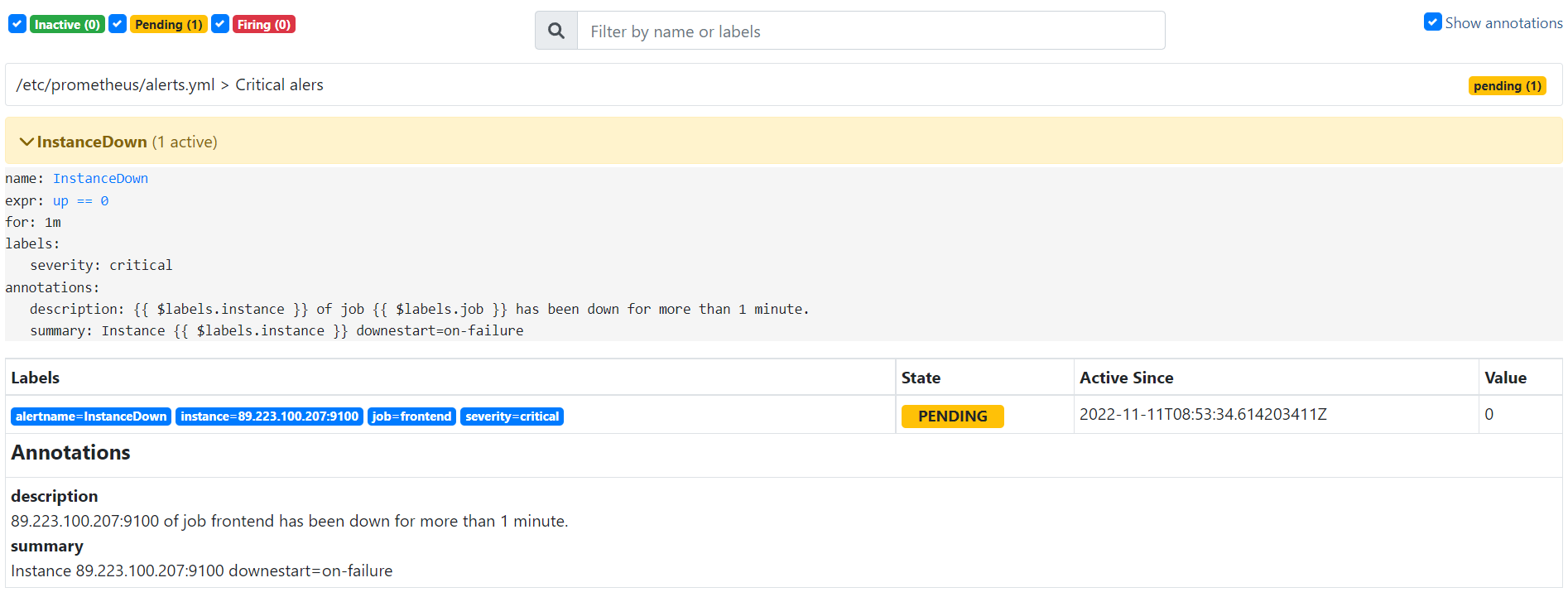
Наш алерт встал в статус PENDING — в ожидании срабатывания. Это значит, что условие алерта выполнено частично. Как только условие будет выполнено полностью мы увидим полноценный красный алерт:
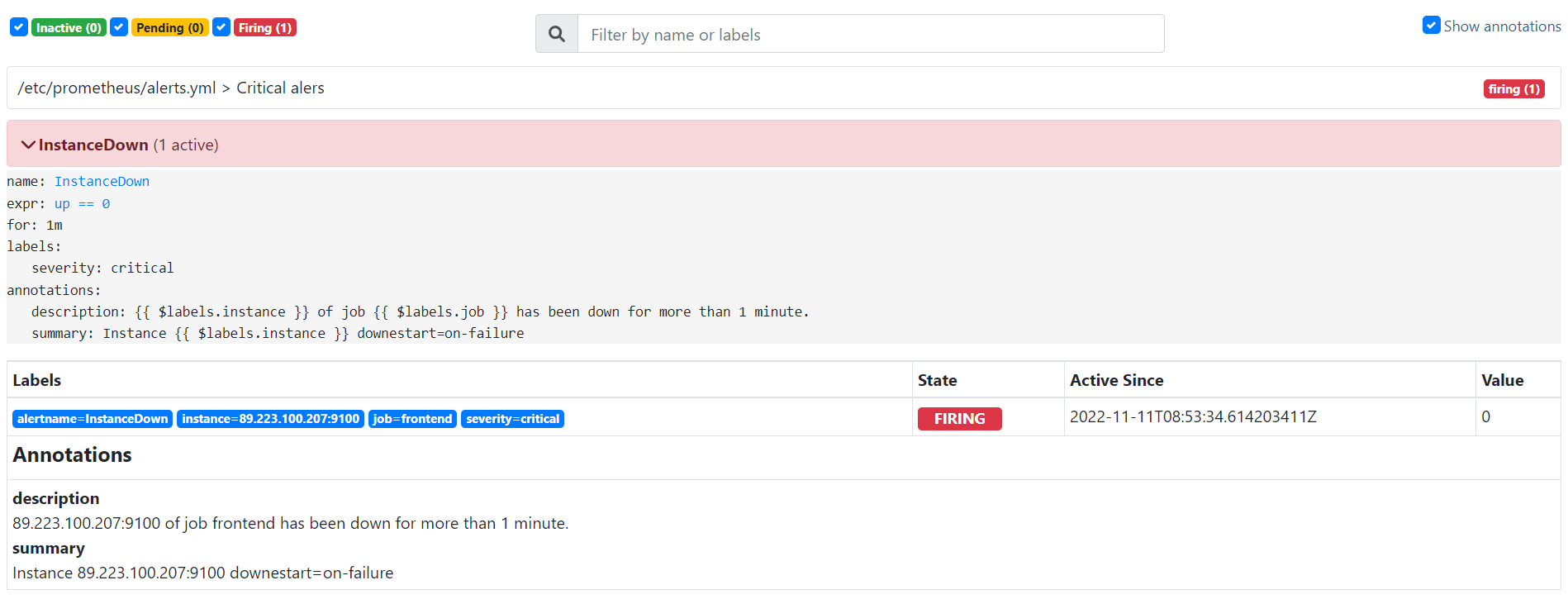
Отлично, наше правило работает исправно. Умение составлять правила для AlertManager — это полноценный скилл, такой же редкий и нужный, как умение написания Nginx-конфигов. Для того чтобы писать алерты было легче, разработчики Prometheus сделали отдельный сайт, содержащий огромное количество примеров написания алертов на все случаи жизни — Awesome Prometheus alerts, а чтобы вам было легче разобраться в том, как вообще писать алерты — рассмотрим из чего состоит алерт:
groups: #Группы алертов - name: Critical alert #Название группы алертов rules: #Секция правил по которым будет срабатывать alert - alert: InstanceDown #Название алерта expr: up == 0 #Условие срабатывания алерта for: 1m #Время через какое сработает alert labels: #Метки группировки алертов severity: critical #Уровень важности алерта annotations: #Секция описания алерта description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minute.' #Заголовок алерта summary: Instance {{ $labels.instance }} downestart=on-failure #Описание алерта
В описании алерта можно использовать переменные для предоставления большей информации об инциденте. Вот некоторые переменные, которые можно использовать:
- {{$labels.instance}} — IP-адрес и порт экспортера хоста, который создал алерт;
- {{$labels.job}} — имя задачи из конфигурационного файла prometheus.
Всё, теперь алерты отображаются у нас в Prometheus корректно. Осталось настроить AlertManager так, чтобы он слал нам уведомления в Telegram. Тема непростая и подробно развернуть её в рамках данной статьи — идея плохая, поэтому мы сделали отдельный гайд: Настройка уведомлений из Prometheus в Telegram.
Отлично, вроде со всем, что касается AlertManager для общей работы разобрались. Давайте резюмируем, что нового мы узнали об AlertManager и сделаем финальный вывод по статье.
Кратко об AlertManager
AlertManager — это программа, которая получает алерты от Prometheus, обрабатывает их и формирует оповещения об инцидентах. AlertManager так же как и node exporter и Prometheus устанавливает отдельно из репозитория. Настраивается AlertManager через собственный конфигурационный файл, написанный в yml-формате.
С помощью AlertManager можно гибко настраивать условия и каналы оповещения об инцидентах. Например, можно настроить уведомления на почту или в Telegram. Устанавливается AlertManager так же как и node exporter или Prometheus из официального репозитория разработчиков с помощью wget или git clone.
Что мы узнали о Prometheus?

Prometheus — это система сбора и хранения метрик в формате временных рядов, а также система оповещения об инцидентах. Prometheus предоставляет доступ к метрикам через web-интерфейс на порте 9100. Запросы к метрикам осуществляются на языке PromQL, который позволяет совершать различные математические действия с метриками и выводить результат в табличном или графическом виде.
Prometheus можно запустить как отдельное приложение на сервере и сделать его демоном с помощью systemd или запустить его в контейнере. Однако, сам по себе Prometheus не самостоятелен, для формирования полноценной системы мониторинга ему нужны дополнительные элементы: экспортеры (exporters) и менеджер алертов(alertmanager).
Exporters — это программы, которые устанавливаются на наблюдаемые серверы и предоставляют доступ к метрикам в формате plain-text на заданном http-порте. Экспортеров много и многие из заточены для съёма метрик с определенного ПО. Например, Postgres exporter собирает метрики работы PostgreSQL сервера, а node exporter собирает метрики системы.
Каждый экспортер работает на своем порте: node exporter — 9100, Memcached exporter — 9150, Postgres exporter 9187 и т.д. Формат данных — text-plain html. Экспортеры можно тонко настроить на сбор определенных групп метрик. Сами по себе экспортеры почти не отнимают ресурсов и представляют собой маленькие бинарные файлы, которые обычно запускаются в качестве демонов с помощью systemd. Данные от экспортеров собирает Prometheus, обрабатывает их, формирует алерты и передает их в AlertManager.
AlertManager — это небольшая программа, которая получает алерты от Prometheus, обрабатывает их, группирует и формирует оповещения об инцидентах. Основная фишка AlertManager в том, что он позволяет гибко настроить условия формирования оповещений и может рассылать их разным каналам: начиная от электронной почты, заканчивая Telegram.
Вместе эти 3 элемента составляют единую систему мониторинга, которая может быть как локальной — все элементы системы находятся на одном сервере, так и распределенной — каждый элемент системы мониторинга находится на отдельном сервере. Локальную систему мониторинга используют, когда нужно мониторить состояние одного сервера, а распределенную — когда наблюдаемых серверов множество.
Вне зависимости от типа системы мониторинга их используют в сочетании с системой визуализации данных. Обычно это Grafana. О том как подружить Prometheus и Grafana так, чтобы выжать максимум из этого симбиоза, мы расскажем в следующей статье. Пока мы готовим новый материал, рекомендуем ознакомиться со статьями, которые помогут вам лучше разобраться в теме работы с системами мониторинга:
Grafana на VPS: установка и настройка
Разбираемся, как работают системы мониторинга нагрузки на примере графаны.
Введение в IaC и знакомство с Ansible
Знакомимся с IaC и Ansible: какие задачи они решают и как работают.

YAML для начинающих
Учим синтаксис YAML, сравниваем его с XML, смотрим как его интерпретирует Python.