
Контейнеры, микросервисы, Docker, Kubernetes и ещё +100500 непонятных слов и аббревиатур 🤯. Если вы считаете себя единственным, кто всего этого не понимает, не волнуйтесь — вы далеко не один!
В этой статье разберемся в основах контейнеризации, рассмотрим конкретные технологии контейнеризации приложений, а в следующих публикациях углубимся в тему и пройдемся по Docker и Kubernetes. Готовы? Отдать швартовы — отходим 🚢.
Основа контейнеризации — ядро Linux
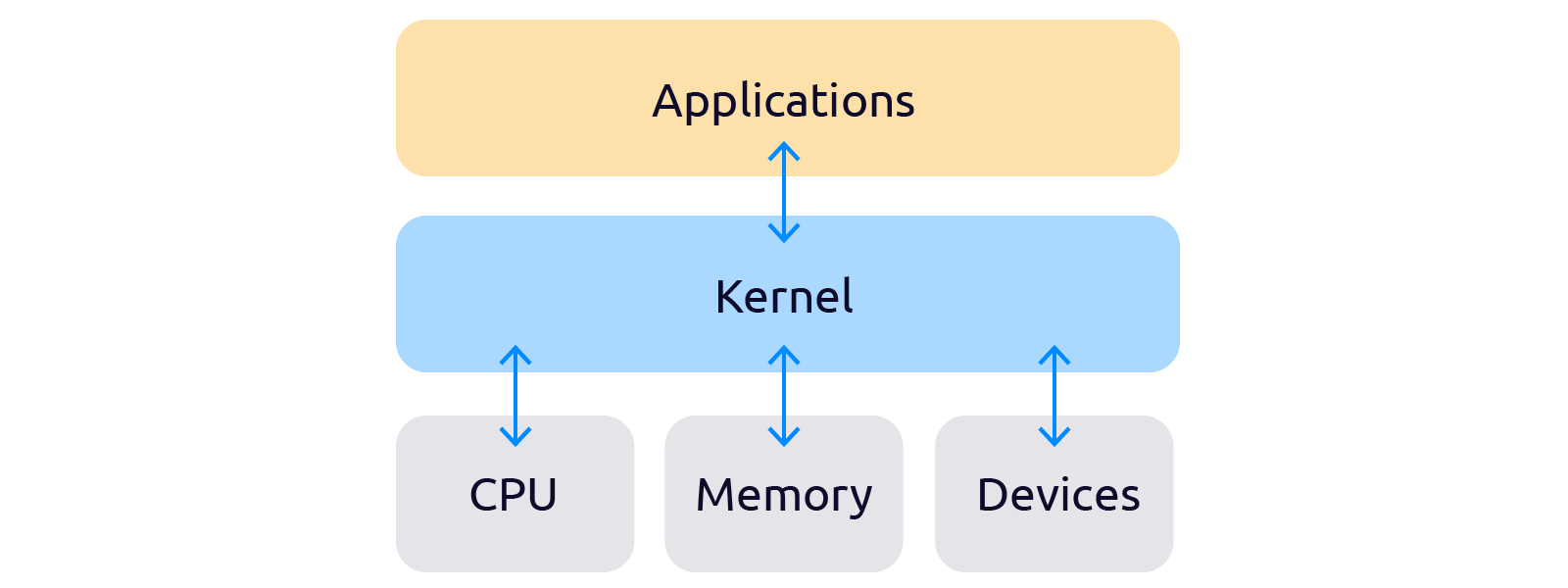
Контейнер — это изолированная рабочая среда, содержащая все зависимости, конфигурационные и исполняемые файлы необходимые для работы программы или пользователя, находящегося в контейнере. Для работы контейнера ОС выделяет пул изолированных ресурсов: ядра ЦП, оперативная память, диск и сеть.
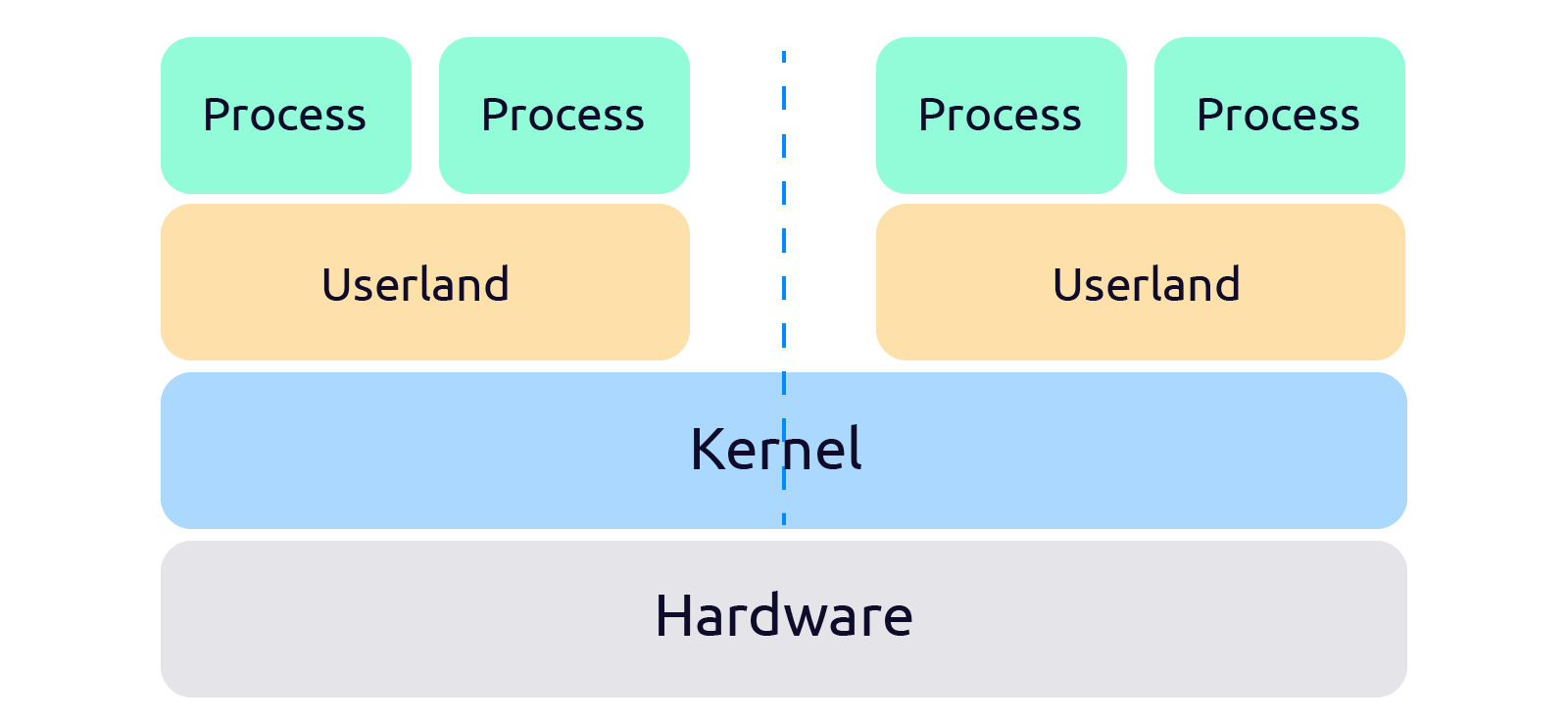
Важно понять, что контейнер работает на ядре хостовой ОС и изолируется средствами операционной системы, а не возможностями железа, как виртуальная машина.
Пока в Linux существуют всего несколько инструментов ядра, которыми можно изолировать процессы и ограничить доступ к ресурсам. С помощью Namespaces (неймспейсы) процессы можно объединить в группы и изолировать, а с помощью Cgroups можно задать лимиты по ресурсам.
Namespaces и Cgroups мы разберём чуть позже, а пока взглянем на функцию изоляции процессов на уровне ядра ОС, которой пользовались задолго до появления Namespaces и Cgroups — chroot.
Первый механизм изоляции процессов — chroot
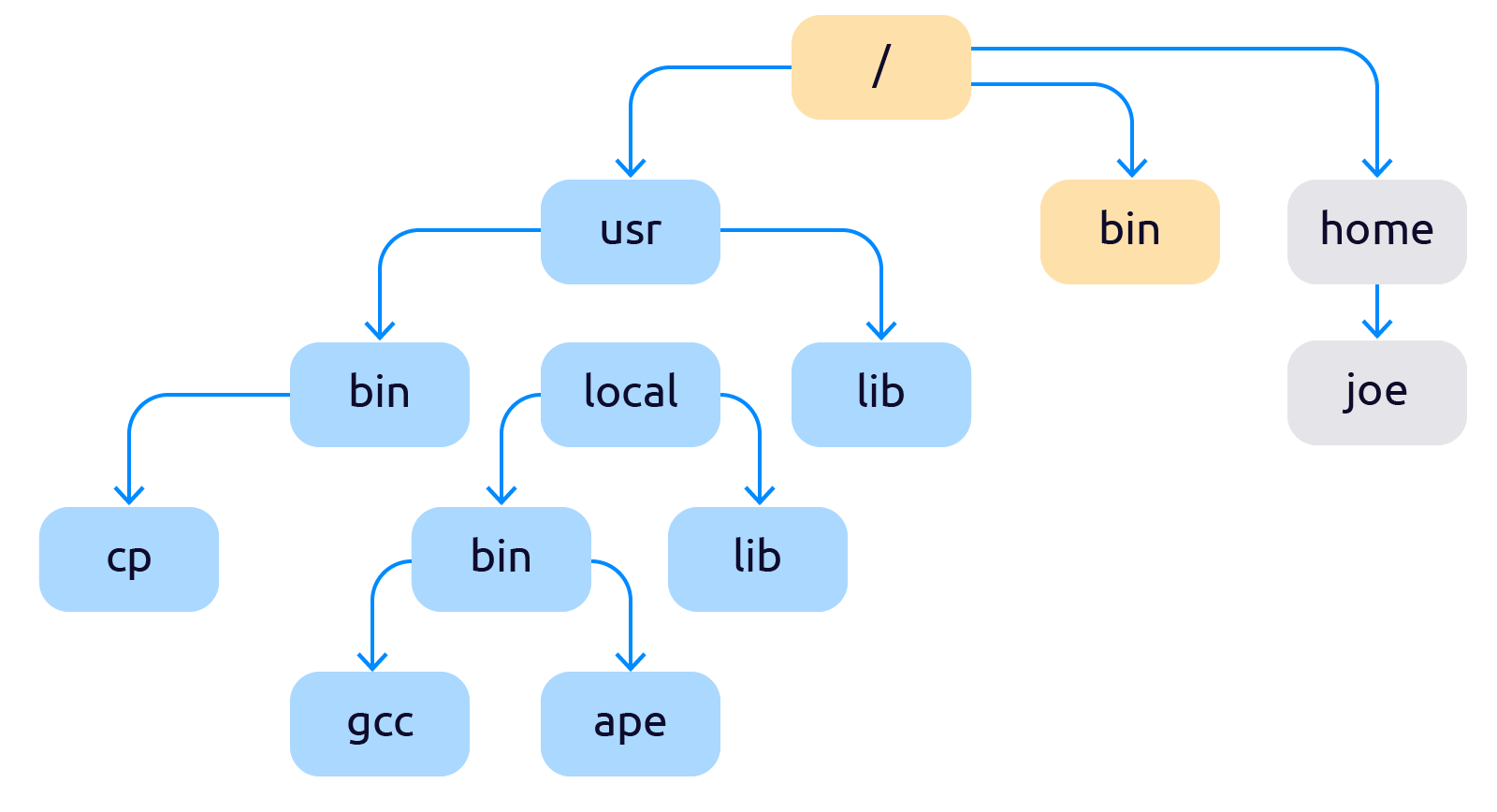
Про механизмы разделения процессов на изолированные окружения начали думать ещё в конце 70-х. Первым механизмом управления изоляцией процессов стал — chroot (чрут).
Chroot — это подмена корня файловой системы для группы процессов или временная смена корня и контекста для запуска выбранных процессов. Точнее сказать так: chroot добавляет в систему второй корневой каталог «/», который с точки зрения пользователя ничем не будет отличаться от первого.
После применения чрута файловая система начинает выглядеть как-то так:
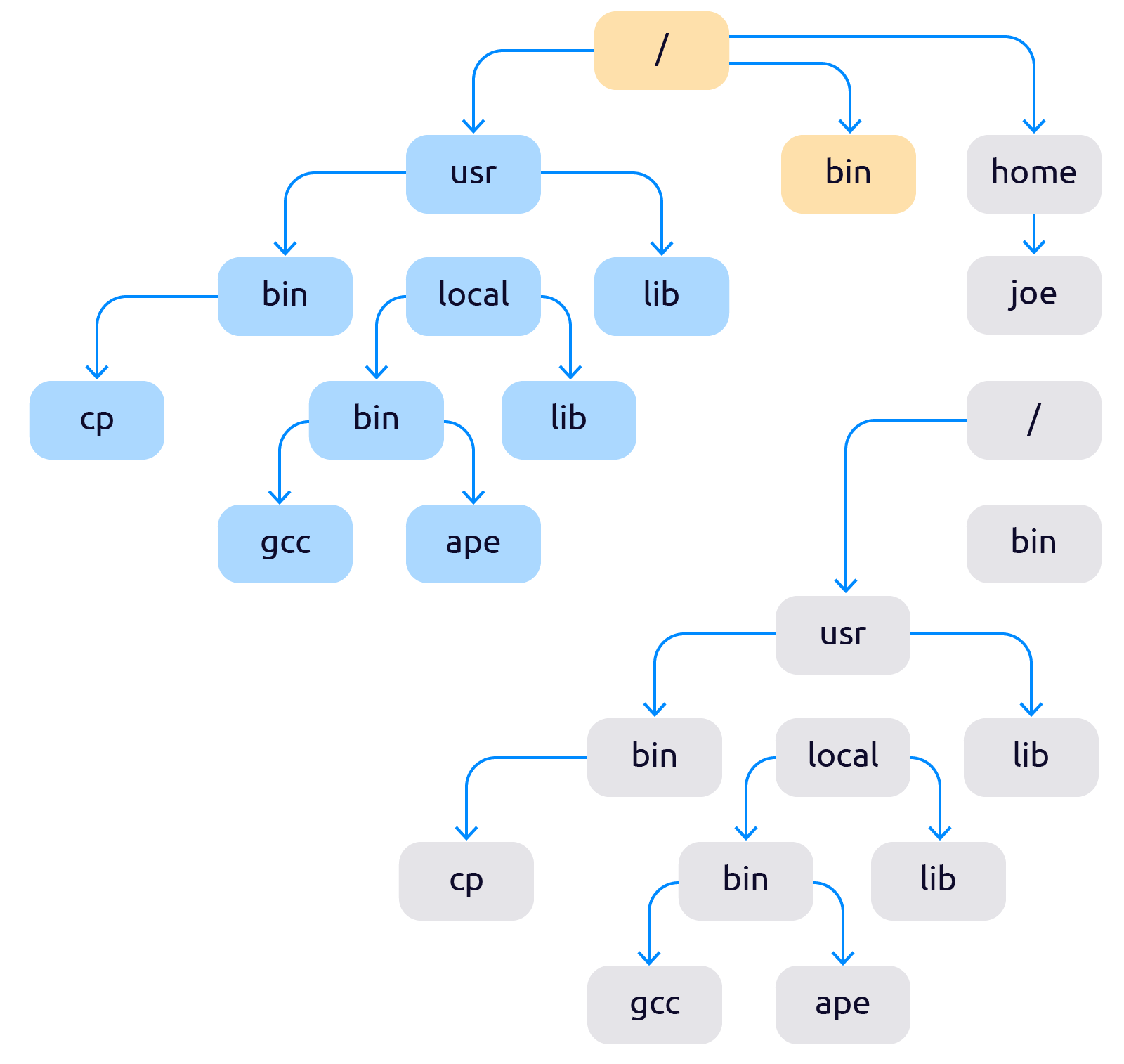
Теперь файловая система разделена на две не влияющие друг на друга части.
Сейчас chroot стандартная функция любой *nix-ОС. Появившись впервые в 1982, в BSD 4.2, он почти не изменился, отсюда такое обилие недостатков:
- Общие пространство процессов — процесс запущенный в chroot видит все остальные процессы.
- Сеть общая — невозможно запустить изолированные серверы в разных чрутах.
- Нельзя назначить лимиты по ресурсам — в любой момент процесс из чрута может так же, как и любой другой процесс в системе аллоцировать все ресурсы.
В каких задачах chroot применяется до сих пор:
- ограничение прав анонимных пользователей, подключившихся по ftp-протоколу
- управление правами пользователей, подключившихся по ssh-протоколу.
Chroot служит для изоляции процессов. Например, bind во многих дистрибутивах Linux запускается в chroot, многие демоны перед понижением привилегий делают chroot в пустую директорию. Также chroot может изолировать пользователей — демоны ftp и ssh через chroot ограничивают права анонимных пользователей.
Если вам хочется попробовать chroot на практике и поупражняться в Linux-администрировании. Рекомендуем прочесть эту статью.
Chroot был самым простым и единственным способом изоляции процессов в течение 15 лет, пока не появился jail.
Первый контейнер — технология jail в FreeBSD 4.0
Jail появился в 1999-2000 годах, в FreeBSD 4.0. По факту jail — это тот же chroot только посложнее. В jail появилась изоляция сети. Однако во FreeBSD, это изоляция была половинчатой — сетевые интерфейсы были видны в любом окружении, но в зависимости от окружения были видны только определённые IP-адреса, которые были присвоены определенным интерфейсам. При этом loopback был общим.
Jail был уже намного продвинутее чрута, и на нём даже строили хостинги, однако ограничения ресурсов в нём по-прежнему не было. Назначать лимиты на ресурсы стало возможно лишь в FreeBSD версии 9.0, с появлением механизма управления ресурсами RCTL. Эта система позволяет ограничивать ресурсы как отдельным пользователям и процессам, так и целым jail.
Интересный факт
В мире кроме всем нам хорошо известных Linux и Windows есть много самописных ОС, которые, конечно, в качестве основы брали уже что-то готовое от других ОС, но при этом приносили и что-то неожиданное и оригинальное.
Такой ОС непохожей на все остальные была Plan9. Это ОС разработана в Bell labs. Её исходники опубликованы на рубеже 00-х.
Фишка Plan9 в отношении к идеологии *NIX. Постулат *NIX — «всё есть файл».

Однако сокеты в *NIX-системах не вписываются в эту абстракцию, а вот в Plan9, сокет — это тоже файл.
Разработчики Plan9 возвели идеологию *NIX-систем в абсолют. В будущем Plan9 вдохновит немало других ОС, таких, как Harvey OS и Jehanne OS.
Примерно в то же время, в начале 2000 на свет появилась Virtuozzo в качестве коммерческой контейнеризации и openvz. Однако неудачные попытки коммерциализации продукта сильно затормозили приход новой системы контейнеризации в массы.
Немного о свободном ПО и коммерциализации
Если бы Parallels, Inc последовали бы сразу заветам Ричарда Столлмана, о коммерциализации open source-проектов, исходя из его заветов: зарабатывать open source может только на платном суппорте и платной доработке фич, возможно, судьба Virtuozzo сложилась бы по другому.
Кстати, Столлман ещё тот олдфаг. На своих выступлениях и лекциях он часто призывает отказаться от сотовых телефонов и передачи своих личных данных третьим сторонам.

Вообще мировоззрения Ричарда сегодня могут многим показаться устаревшими и недееспособными, однако на фоне этого, все же невозможно отрицать его огромный вклад в развитие свободного ПО.
Ознакомиться с биографией Ричарда Мэттью Столмана можно в Википедии.
К тому же, в те же годы к разработчикам стало приходить понимание, что все существующие инструменты изоляции — это костыли и палки проросшие глубоко в ядро ОС, и нужно радикально менять подход.
Для более глубокого погружения в jail рекомендуем прочесть вот эту статью на Хабре. Внутри много кода и подробная инструкция по настройке jail.
Переломный момент — появление Namespaces
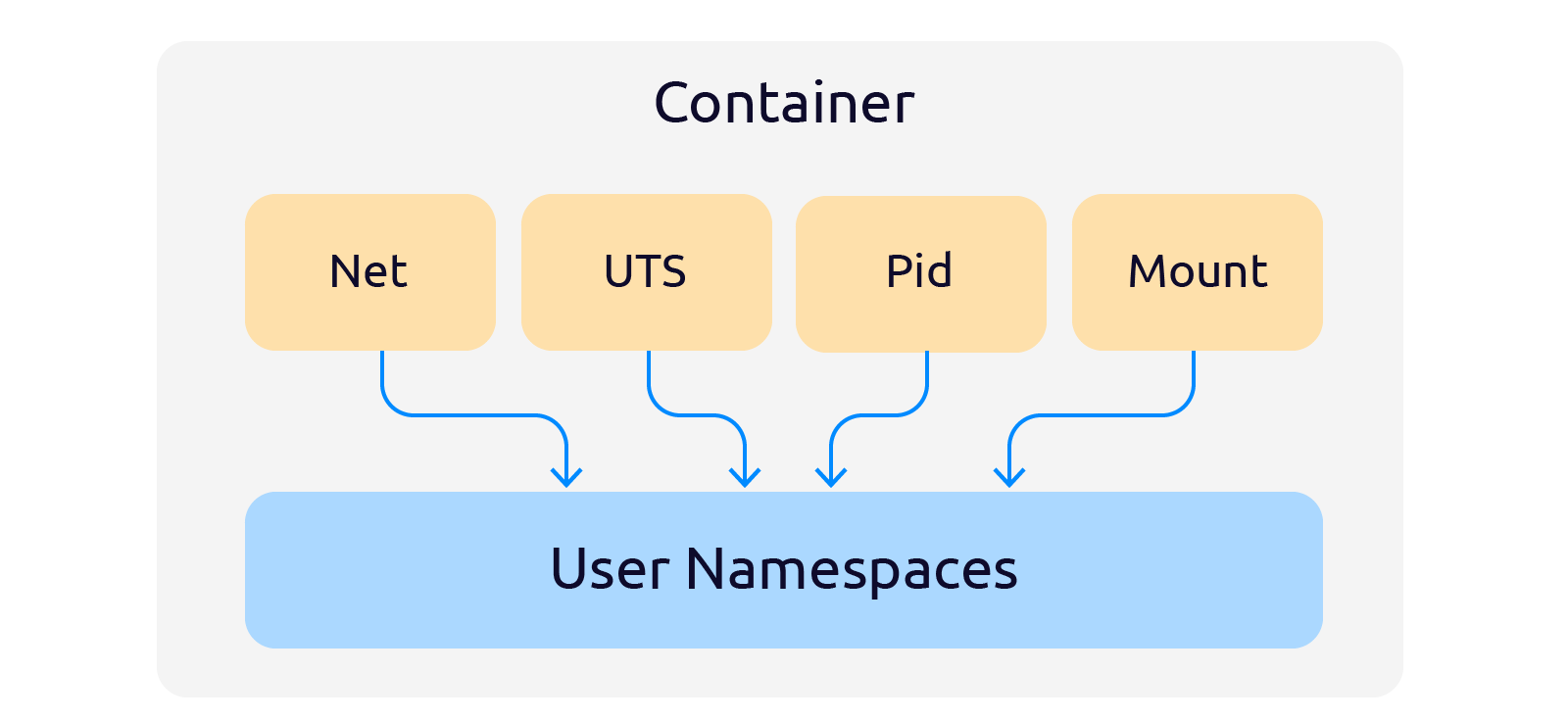
Свежим глотком воздуха стало появление в 2002 году, в ядре Linux версии 2.4.19 нового API для создания абстракции контроля над общими ресурсами — Namespaces API.
Namespaces (пространства имен) — это абстракция (программная прослойка) над физическими ресурсами. Если раньше процессы обращались напрямую к ресурсам, то с появлением namespaces, все запросы проходят через этот дополнительный слой абстракции.
С появлением namespace в ядро было добавлено 3 новых функции, которые отвечают за управление атрибутами namespace:
- clone() — аналог fork() с возможностью выделения частей общих ресурсов в отдельные namespaces.
- setns() — подключает указанный процесс к заданному namespace.
- unshare() — изменение контекста текущего процесса.
В результате вызовов перечисленных функций ядра, namespaces становятся новыми атрибутами процессов. Это позволяет разным процессам иметь разное представление о тех глобальных ресурсах, которыми они распоряжаются.
Существуют следующие пространства имён:
- Mount — абстракция над пространством имен для файловых систем. Mount позволяет сразу монтировать новое устройство в несколько пространств имён файловой системы, вместо монтирования в каждом отдельном пространстве.
- Network — абстракция над сетью: интерфейсы, таблицы маршрутизации и т.д. Пространство имен Network по сути выполняет роль туннеля между разными пространствами имён сети.
- IPC — абстракция над межпроцессным взаимодействием. Процесс в пространстве имен IPC не может писать или читать IPC ресурсы, принадлежащие другому пространству имен. Так процессы в одном контейнере не могут вмешиваться в другие контейнеры.
- PID — абстракция над пространством номеров процессов. PID изолирует пространство ID процессов. Процессы в различных пространствах могут иметь одинаковые ID.
- User — абстракция над пространством пользователей. User изолирует ID пользователей и групп, корневой каталог, ключи и capabilities.
- UTS (Unix Time Sharing) — абстракция над пространством hostname и NIS. UTS позволяет контейнерам иметь собственные доменные имена NIS domainname и имена контейнеров nodename.
- Cgroup — используется как атрибут, корневой узел дерева cgroup.
Перечисленные неймспейсы появлялись постепенно, по-мере необходимости решения определенных технических задач. Контейнер, по сути можно назвать квинтэссенцией неймспейсов. Вообще, тема неймспейсов очень обширна. Если вы хотите разобраться в ней лучше — почитайте этот отличный цикл статей на Хабре.
Неймспейсы решили вопросы изоляции, однако вопрос ограничения ресурсов для изолированных процессов оставался открытым. Решение этого вопроса появилось с выходом ядра версии 2.6.20 в 2008 году — в нём появился механизм Cgroups.
Ограничение ресурсов — Cgroups
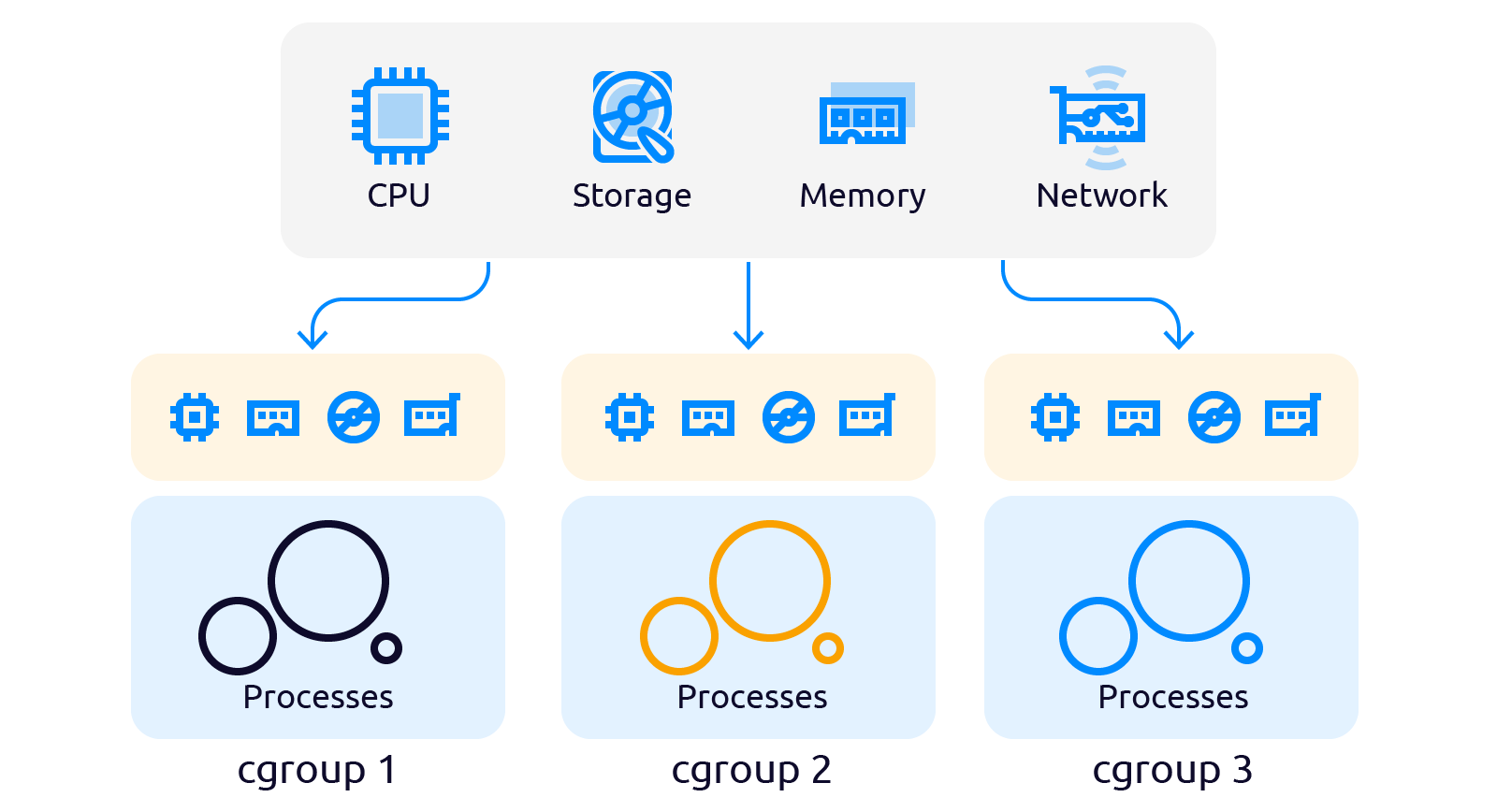
Cgroups (control group) — группа процессов Linux, на которые наложена изоляция и установлены ограничения на вычислительные ресурсы (процессорные, сетевые, ресурсы памяти, ресурсы ввода-вывода) со стороны ядра Linux.
Cgroups — было отличное самодостаточное решение, которое сильно продвинуло технологии контейнеризации вперед. Первой попыткой создания подобного механизма лимитирования ресурсов для изолированных процессов был process accounting, появившийся в 1999 году.
Опять же не обошлось без Google
Google — компания, которая умеет идти своей дорогой, даже там, где дороги вроде бы и нет.
В 2006 году Google взялась за разработку собственного механизма управления ресурсами контейнеров — process containers. Разрабатывали механизм Пол Менедж и Рохит Сет.
Замысел был скромен — усовершенствовать механизм cpuset, предназначенный для распределения процессорного времени и памяти между задачами. Но обыкновенная палка в руках опытных разработчиков выстрелила!
В итоге в конце 2007 года название process containers было заменено на control groups, а в 2008 году cgroups был официально добавлен в ядро Linux (версия 2.6.24).
Разработанные в Google и, включенные в ядро в 2008 году Cgroup стали новой абстракцией над управлением ресурсами. Cgroups состоит из двух частей: cgroup core (ядро cgroup) и подсистем (директории с управляющими файлами).
Количество подсистем может отличаться в зависимости от версии ядра. Так в ядре версии 4.4.0.21 таких подсистем 12, в ядре версии 5.10.16.3, которое содержится в Ubuntu 20 TLS, подсистем уже 13:
- blkio — управляет лимитами чтения и записи на блочных устройствах;
- cpu — управляет доступом к ресурсам процессора;
- cpuset — выделяет отдельных процессоров группе;
- cpuacct — управляет ресурсами cpu (работает совместно с cpu);
- devices — ограничивает доступ к устройствам;
- hugetlb — управляет работой групп с большими страницами памяти (huge pages);
- net_cls — размечает спец. тегами сетевые пакеты, что позволяет процессам генерирующим их определять какие процессы их сгенерировали;
- perf_event rdma — предоставляет интерфейс для инструмента анализа производительности в Linux (perf);
- freezer — управляет приостановкой и возобновлением процессов выполнения задач внутри контрольной группы;
- memory — управляет выделением памяти для групп процессов;
- net_prio — управляет динамическим назначением приоритета трафика;
- pids — ограничивает количество процессов в рамках контрольной группы;
- unified — автоматически монтирует файловую систему в каталог /sys/fs/cgroup/unified при запуске системы.
Вывести список подсистем в вашей версии ядра можно следующей командой:
$ ls /sys/fs/cgroup/
blkio cpuacct devices hugetlb net_cls perf_event rdma cpu cpuset freezer memory net_prio pids unified
Посмотреть к каким контрольным группам принадлежит процесс можно так:
- вызовите утилиту htop
- найдите нужный вам PID процесса
- перейдите в каталог /proc и найдите там директорию с нужным вам PID
- вызовите команду cat и передайте ей cgroup
$ cd /proc/PID/
$ cat cgroup
39:rdma:/
38:pids:/
37:hugetlb:/
36:net_prio:/
35:perf_event:/
34:net_cls:/
33:freezer:/
32:devices:/
31:memory:/
30:blkio:/
29:cpuacct:/
28:cpu:/
27:cpuset:/
0::/
Как работать с Cgroups
Работать с cgroups можно двумя способами:
- Стандартным способ — работать с cgroups как с файлами. Вносить записи групп с помощью echo в нужный контроллер.
- С помощью cgroup-tools — работать с cgroups через набор утилит, которые облегчают взаимодействие с cgroups.
Первый способ более предпочтительный, но более трудозатратный для пользователей, имеющих не богатый опыт администрирования Linux, поэтому мы пойдем вторым путем — будем использовать cgroup-tools.
Поместить процесс в контрольную группу просто. Достаточно выполнить команду cgcreate, передать ей следующие параметры:
- -t uid:gid — пользователи, получающие права на перемещение заданий в (из) группы.
- -a uid:gid — пользователи, получающие права на управление параметрами группы (опциональный параметр).
- -g список подсистем:путь.
Пример создания контрольной группы по памяти и процессору:
$ sudo cgcreate -t root:root -g memory,cpu:/mycgroup
Теперь в нашу вновь созданную группу нужно переместить процессы. Для этого есть команда cgclassify, в которую с помощью ключа g передается группа, её название и пиды процессов:
$ sudo cgclassify -g cpu:/mycgroup 7
Убедится, что процесс попал в новую группу можно с помощью команды cat:
$ cat /proc/PID-номер/cgroup
Удалить процесс из группы можно также одной командой:
$ sudo cgdelete -g memory,cpu:/mycgroup
До этого мы умели лишь создавать группы и помещать в них процессы. Теперь научимся задавать ограничение ресурсов. Делается это командой cgset с параметром -r:
$ cgset -r cpu.shares=1 /mycgroup
Мы рассмотрели несколько основных инструментов управления контрольными группами из пакета cgroups-tools. Их там конечно же куда больше. Полное описание всех утилит пакета можно посмотреть тут.
Кстати, есть и альтернативный способ управления и настройки cgroups, о нём можно узнать из этой статьи:

Итак, мы кратко рассмотрели историю контейнеризации до этапа появления namespaces и cgroups, рассмотрели эти механизмы и теперь можно подвести итог.
Что же такое контейнер в итоге?

По сути контейнер — это определенные пространства имён (Namespaces) и наборы контрольных групп (Control groups), удобно управляемые с помощью сторонних утилит. Например, с помощью Docker.
Namespace — механизм изоляции процессов. Мы можем создавать пространства имён процессов (группы процессов) помещать туда нужные нам процессы по их идентификаторам — пидам (PID) и эти процессы не могут обращаться к процессам вне своего пространства имён.
Control groups — механизм определения количества выдаваемых ресурсов процессам.
Контейнеры обладают следующими важными преимуществами:
- Они легковесные и быстро выполняются, так как содержат только всё необходимое для работы контейнера: исполняемые и конфигурационные файлы, прочие зависимости.
- Хостовая ОС может смотреть внутрь контейнера и видеть дерево процессов. Когда мы смотрим на процесс виртуальной машины с хоста, мы видим один процесс.
- Появляется возможность использовать микросервисную архитектуру. Каждый сервис можно поместить в свой контейнер, назначить ему ресурсы, запускать и останавливать их независимо друг от друга.
- Можно быстрее развертывать приложения, легче масштабировать их горизонтально, проще находить в них ошибки.
- Выход из строя одного контейнера не влияет на дальнейшую работу других контейнеров.
Контейнеры нужны там, где требуется скорость разворачивания приложений и низкий уровень потребления системы виртуализации. Контейнеры подходят:
- для упрощения процесса развертывания приложений;
- для тестирования или отладки кода;
- для запуска приложений, требующих другого дистрибутива ОС (системные контейнеры);
- для микросервисов, которые можно разрабатывать и обновлять независимо;
- для горизонтально масштабируемых приложений — когда запускается несколько одинаковых контейнеров на текущих ресурсах без увеличения стоимости этих ресурсов;
- для модернизации и миграции существующих приложений в более современные среды.
Контейнеризация не подходит, если для работы приложения требуется другая ОС, а не та, что установлена на сервере.
И в конце, мы хотим оставить ссылку на интервью, того, без кого не было бы ни контейнеров, ни Линукса, ни системы контроля версий GIT, да и вообще, не было бы того технологического мира, в котором мы все с вами живём:

В следующих публикациях мы погрузимся в Docker и посмотрим на Docker-контейнеры через уже полученные знания о контейнеризации.